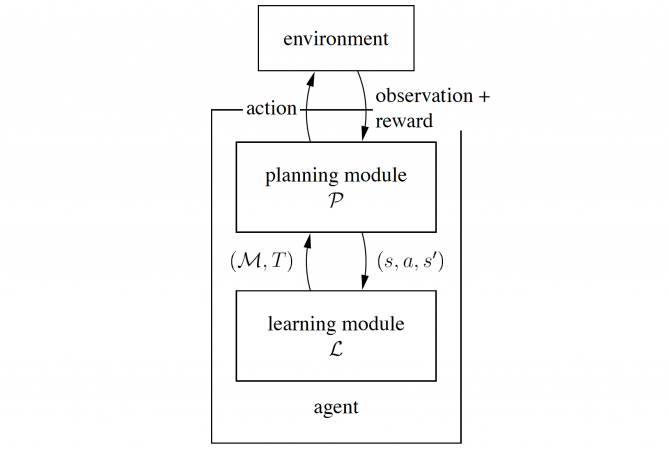
Markov decision processes are mathematical models of an agent’s interaction with its environment, and its attempt to obtain some benefit from this interaction. In the more complicated cases, the agent can only partially observe the state of the environment, and the process is called partially observable.
It may also be the case that the agent doesn’t initially know the rules that govern the interaction, and what the results of its decisions may be. Then the agent has to learn the model from the interaction, a type of learning called reinforcement learning.
In this work we discuss several aspects of reinforcement learning in Markov decision processes in which observability is partial. We introduce the concept of interaction complexity, which is a measure of the rate in which reinforcement learning algorithms extract from the environment useful information. We then explore the interaction complexity of several classes of partially observable decision processes.
Partially Observable Markov Decision Processes (POMDPs) are a central and extensively studied class of decision processes. In some POMDPs, observability is too scarce, and reinforcement learning is not possible. We show a subclass of POMDPs which can be learned by reinforcement, but requires exponential interaction complexity.
We discuss a subclass of POMDPs, called OPOMDPs, in which both planning and learning have been previously studied. We show that reinforcement learning in OPOMDPs is always possible with polynomial interaction complexity.
We then introduce a closely related subclass of POMDPs which we call OCOMDPs. OCOMDPs capture more of the complexities of learning in POMDPs than OPOMDPs do, and efficiently learning them is considerably more difficult to perform and analyze than learning OPOMDPs.
The main result of this thesis is the UR-MAX algorithm for reinforcement learning in OCOMDPs with polynomial interaction complexity. We introduce and discuss the algorithm and some of the intuition behind it, and prove its correctness and efficiency.