Moonwalk: Inverse-Forward Differentiation
Dmitrii Krylov, Armin Karamzade, and Roy Fox
29th Annual Conference on Artificial Intelligence and Statistics (AISTATS), 2026
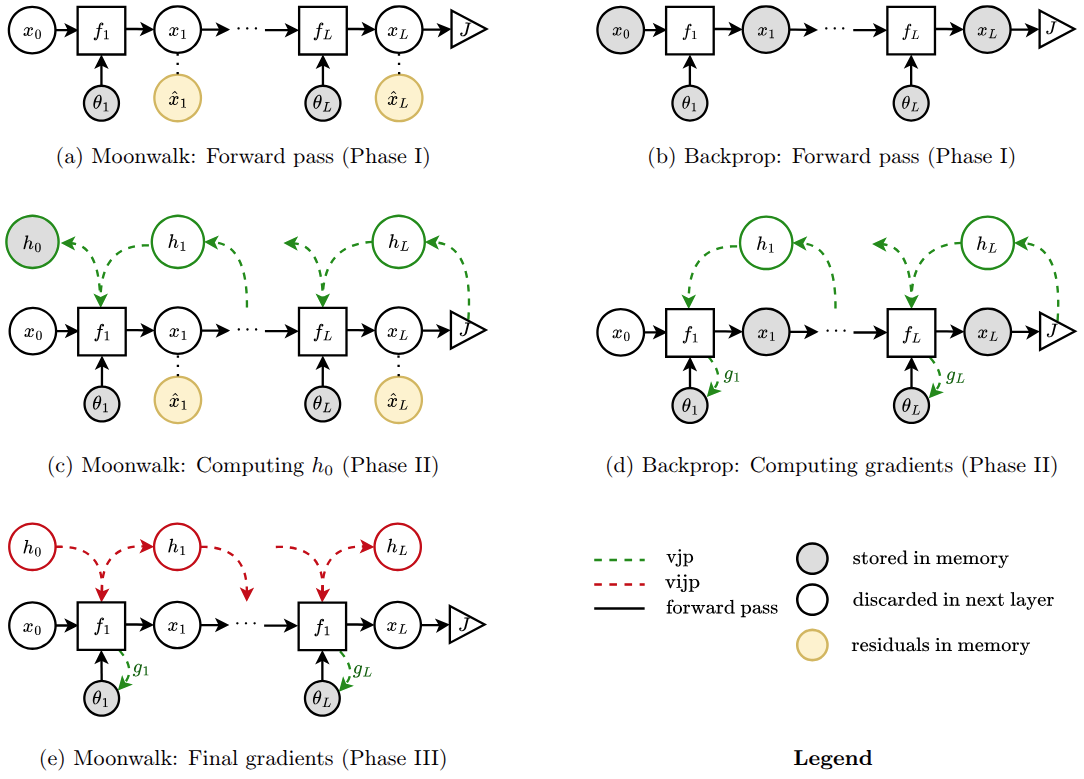
Backpropagation’s main limitation is its need to store intermediate activations, or residuals, during the forward pass, which restricts the depth of trainable networks. This raises a fundamental question: can we avoid storing these activations? In this work, we revisit the structure of gradient computation and show that, for a class of networks we call submersive networks, gradients can be reconstructed exactly without storing activations. Backpropagation computes gradients through a sequence of vector–Jacobian products, an operation that is generally irreversible because information can be lost in the cokernel of each layer’s Jacobian. We introduce the vector–inverse-Jacobian product (vijp), an operator that inverts gradient flow outside this cokernel. For non-submersive layers, we propose fragmental gradient checkpointing, which stores only the minimal residuals needed to recover cotangents erased by the Jacobian. Our method, Moonwalk, first computes input gradients using a memory-efficient backward pass, then reconstructs parameter gradients in a forward sweep without storing activations. We show that Moonwalk matches backpropagation’s runtime while training networks more than twice as deep under the same memory budget.