Ray RLlib: A Composable and Scalable Reinforcement Learning Library
Eric Liang*, Richard Liaw*, Robert Nishihara, Philipp Moritz, Roy Fox, Joseph Gonzalez, Ken Goldberg, and Ion Stoica
Deep Reinforcement Learning symposium (DeepRL @ NeurIPS), 2017
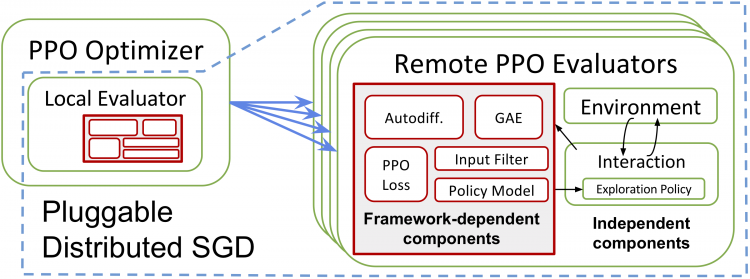
Reinforcement learning (RL) algorithms involve the deep nesting of distinct components, where each component typically exhibits opportunities for distributed computation. Current RL libraries offer parallelism at the level of the entire program, coupling all the components together and making existing implementations difficult to extend, combine, and reuse. We argue for building composable RL components by encapsulating parallelism and resource requirements within individual components, which can be achieved by building on top of a flexible task-based programming model. We demonstrate this principle by building Ray RLlib on top of Ray and show that we can implement a wide range of state-of-the-art algorithms by composing and reusing a handful of standard components. This composability does not come at the cost of performance — in our experiments, RLlib matches or exceeds the performance of highly optimized reference implementations.