Toward Optimal Policy Population Growth in Two-Player Zero-Sum Games
Stephen McAleer, JB Lanier, Kevin Wang, Pierre Baldi, Tuomas Sandholm, and Roy Fox
12th International Conference on Learning Representations (ICLR), 2024
{kind=link}
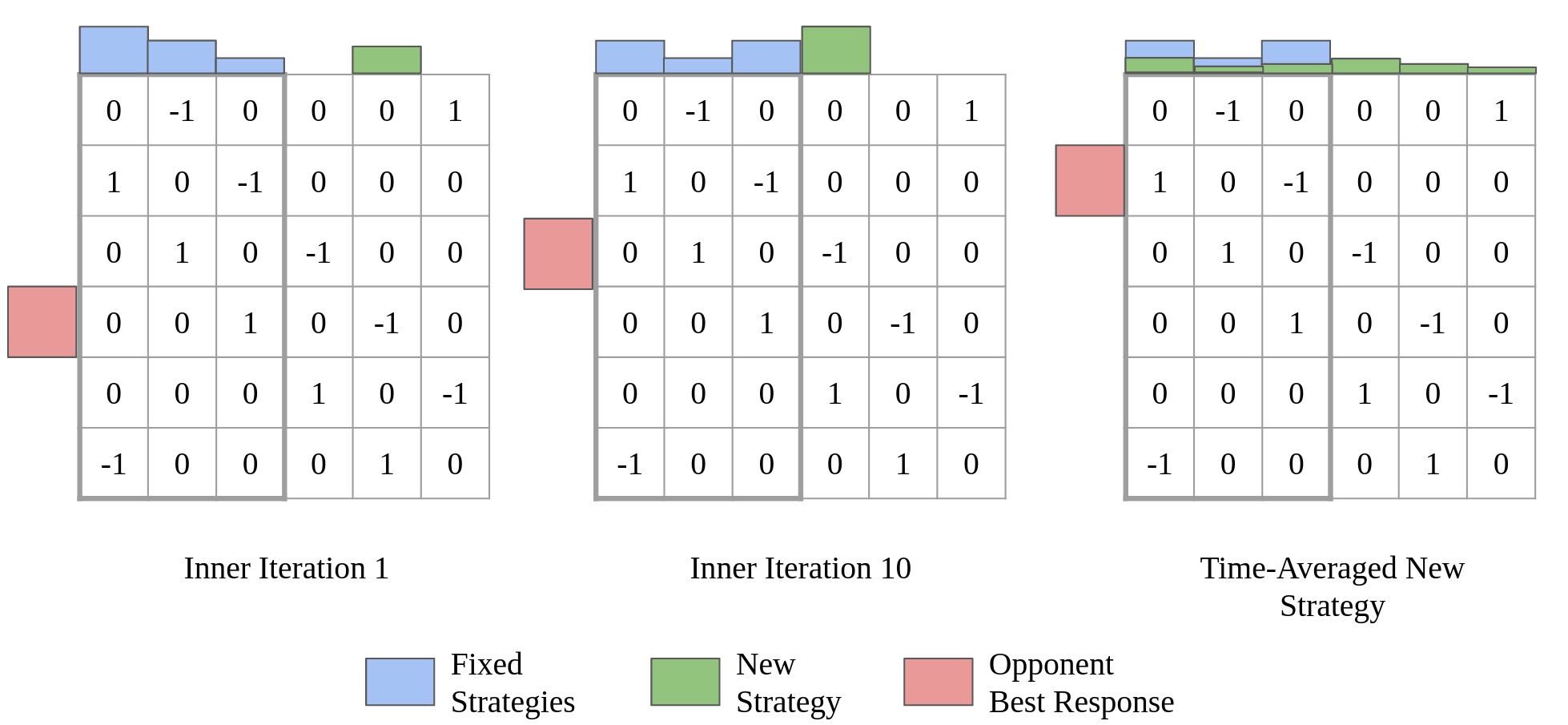
In competitive two-agent environments, deep reinforcement learning (RL) methods like Policy Space Response Oracles (PSRO) often increase exploitability between iterations, which is problematic when training in large games. To address this issue, we introduce anytime double oracle (ADO), an algorithm that ensures exploitability does not increase between iterations, and its approximate extensive-form version, anytime PSRO (APSRO). ADO converges to a Nash equilibrium while iteratively reducing exploitability. However, convergence in these algorithms may require adding all of a game’s deterministic policies. To improve this, we propose Self-Play PSRO (SP-PSRO), which incorporates an approximately optimal stochastic policy into the population in each iteration. APSRO and SP-PSRO demonstrate lower exploitability and near-monotonic exploitability reduction in games like Leduc poker and Liar’s Dice. Empirically, SP-PSRO often converges much faster than APSRO and PSRO, requiring only a few iterations in many games.