Information-Theoretic Methods for Planning and Learning in Partially Observable Markov Decision Processes
Roy Fox
PhD Thesis, 2016
We model the interaction of an intelligent agent with its environment as a Partially Observable Markov Decision Process (POMDP), where the joint dynamics of the internal state of the agent and the external state of the world are subject to extrinsic and intrinsic constraints. Extrinsic constraints of partial observability and partial controllability specify how the agent’s input observation depends on the world state and how the latter depends on the agent’s output action. The agent also incurs an extrinsic cost, based on the world states reached and the actions taken in them.
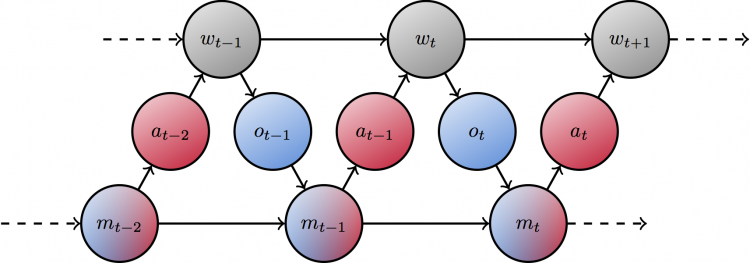
Bounded agents are also limited by intrinsic constraints on their ability to process information that is available in their sensors and memory and choose actions and memory updates. In this dissertation, we model these constraints as information-rate constraints on communication channels connecting these various internal components of the agent.
The simplest is to first consider reactive (memoryless) agents, with a channel connecting their sensors to their actuators. The problem of optimizing such an agent, under a constraint on the information rate between the input and the output, is a sequential rate-distortion problem. The marginal distribution of the observation can be computed by a forward inference process, whereas the expected cost-to-go of an action can be computed by a backward control process. Given this source distribution and this effective distortion, respectively, each step can be optimized by solving a rate-distortion problem that trades off the extrinsic cost with the intrinsic information rate.
Retentive (memory-utilizing) agents can be reduced to reactive agents by interpreting the state of the memory component as part of the external world state. The memory reader can then be thought of as another sensor and the memory writer as another actuator and they are limited by the same informational constraint between inputs and outputs.
In this dissertation we make four major contributions detailed below and many smaller contributions detailed in each section.
First, we formulate the problem of optimizing the agent under both extrinsic and intrinsic constraints and develop the main tools for solving it. This optimization problem is highly non-convex, with many local optima. Its difficulty is mostly due to the coupling of the forward inference process and the backward control process. The inference policy and the control policy can be optimal given each other but still jointly suboptimal as a pair. For example, if some information is not attended to it cannot be used and if it is not used it should optimally not be attended to.
Second, we identify another reason for the challenging convergence properties of the optimization algorithm, which is the bifurcation structure of the update operator near phase transitions. We show that the update operator may undergo period doubling, after which the optimal policy is periodic and the optimal stationary policy is unstable. Any algorithm for planning in such domains must therefore allow for periodic policies, which may themselves be subject to an informational constraint on the clock signal.
Third, we study the special case of linear-Gaussian dynamics and quadratic cost (LQG), where the optimal solution has a particularly simple and solvable form. Under informational constraints, the forward and the backward processes are not separable. However, we show that they do have a more explicitly solvable structure; namely, a sequential semidefinite program. This also allows us to analyze the structure of the retentive solution under the reduction to the reactive setting.
Fourth, we explore the learning task, where the model of the world dynamics is unknown and sample-based updates are used instead. We focus on fully observable domains and measure the informational cost with the KL divergence, so that the problem can be solved with a backward-only algorithm. We suggest a schedule for the tradeoff coefficient, such that more emphasis is put on reducing the extrinsic cost and less on the simplicity of the solution, as uncertainty is gradually removed from the value function through learning. This leads to improved performance over existing reinforcement learning algorithms.