Publications tagged "Multi-agent"
Conferences
Toward Optimal Policy Population Growth in Two-Player Zero-Sum Games
Stephen McAleer, JB Lanier, Kevin Wang, Pierre Baldi, Tuomas Sandholm, and Roy Fox
12th International Conference on Learning Representations (ICLR), 2024
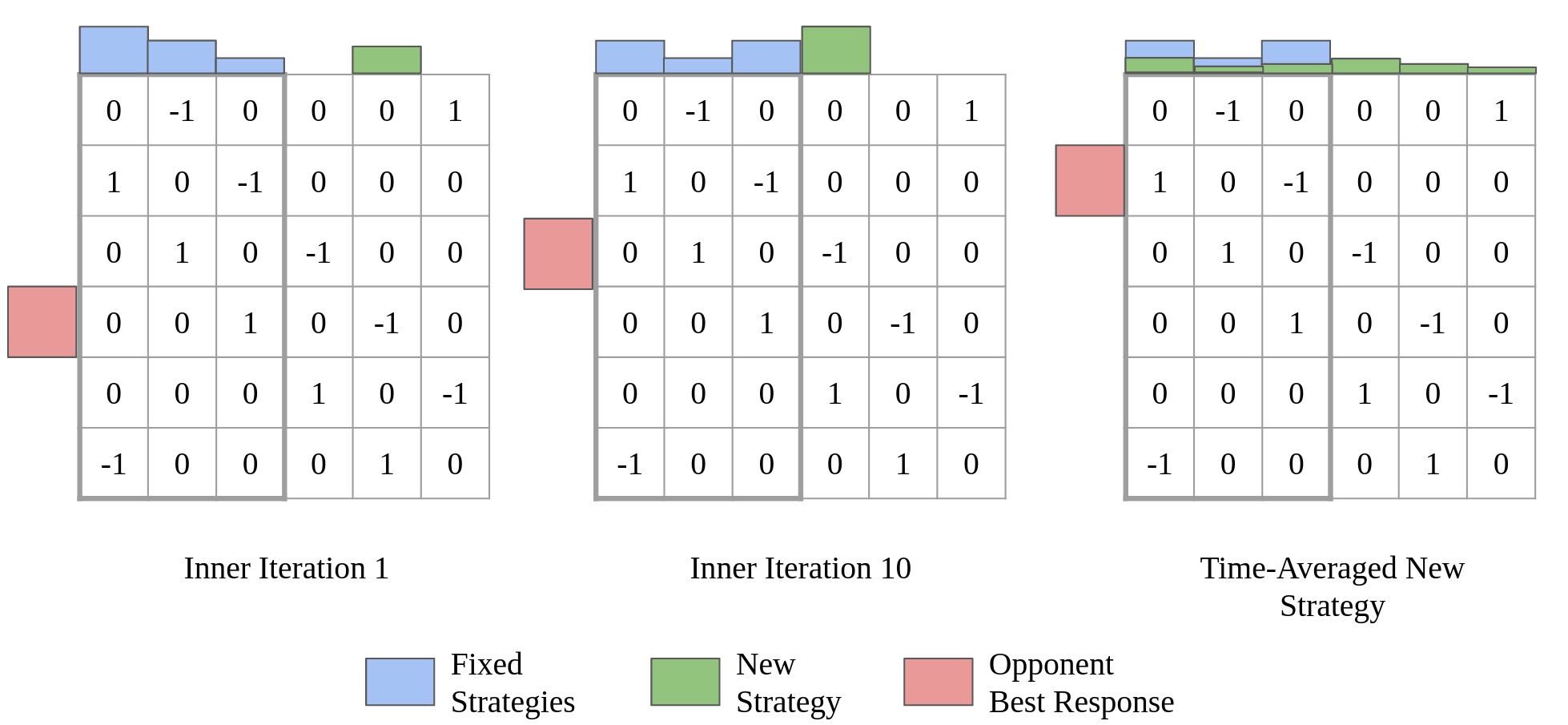
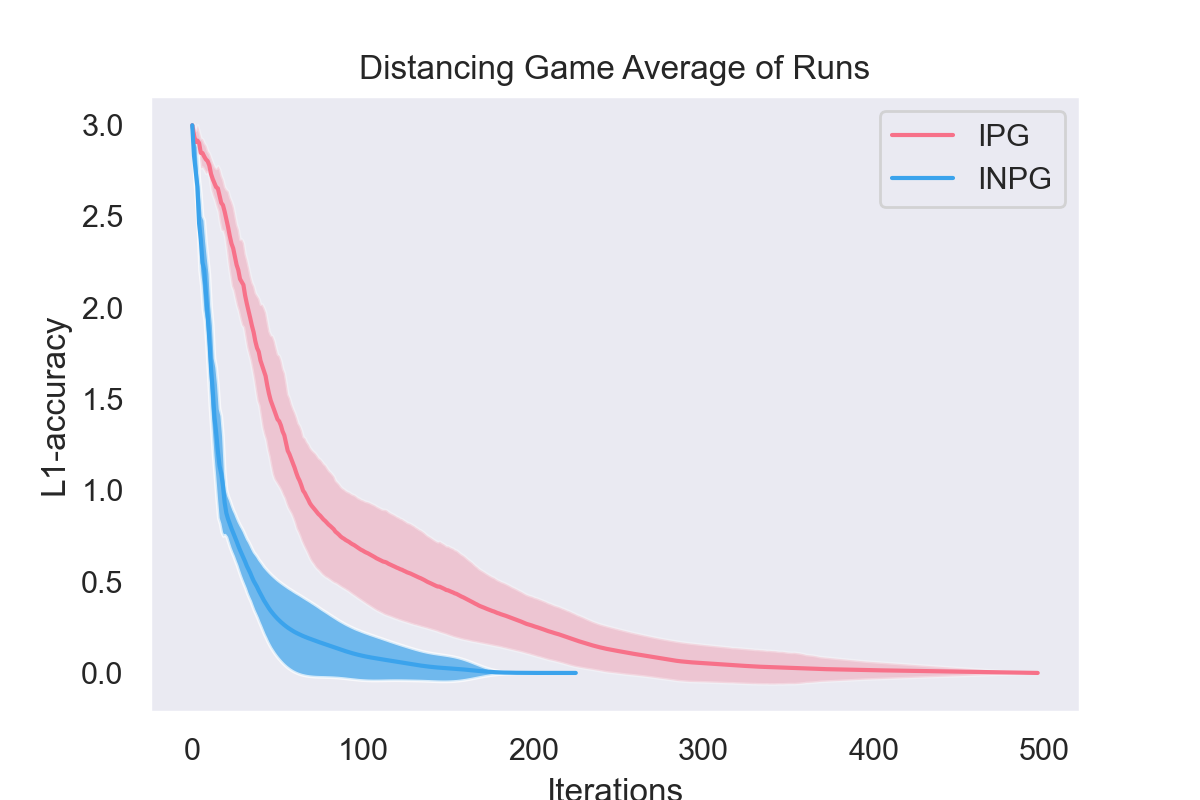
Independent Natural Policy Gradient Always Converges in Markov Potential Games
Roy Fox, Stephen McAleer, William Overman, and Ioannis Panageas
25th International Conference on Artificial Intelligence and Statistics (AISTATS), 2022
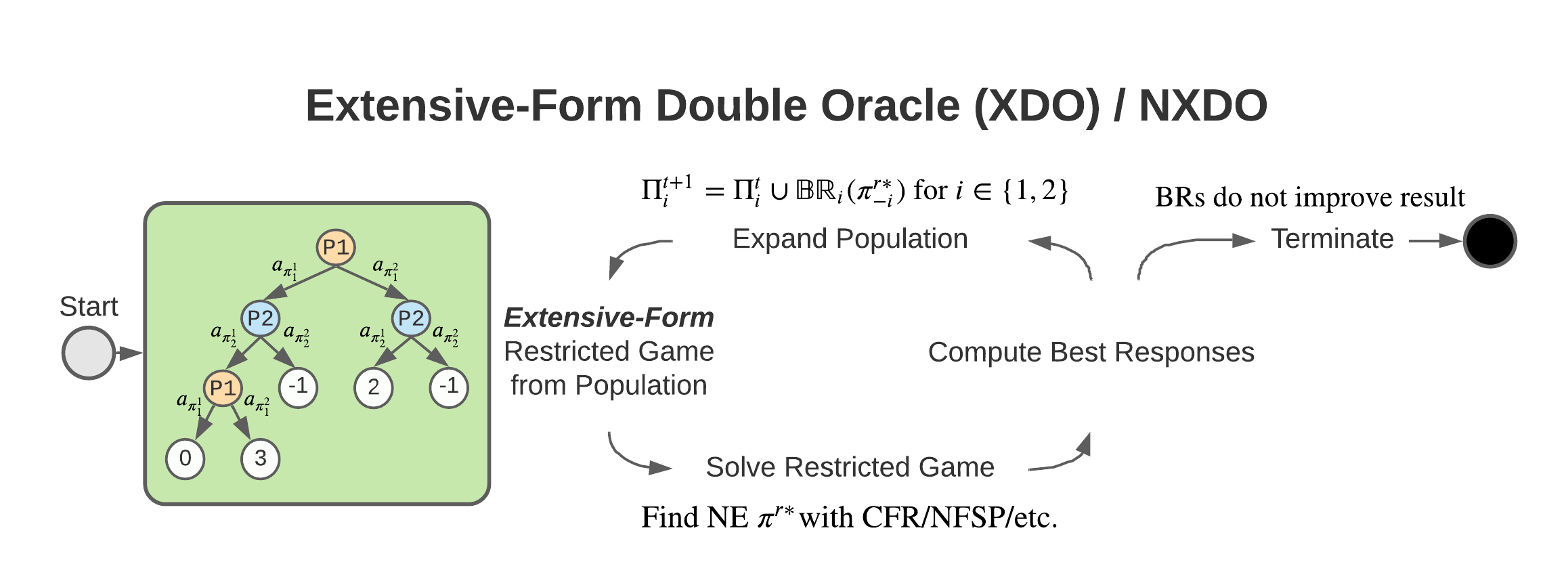
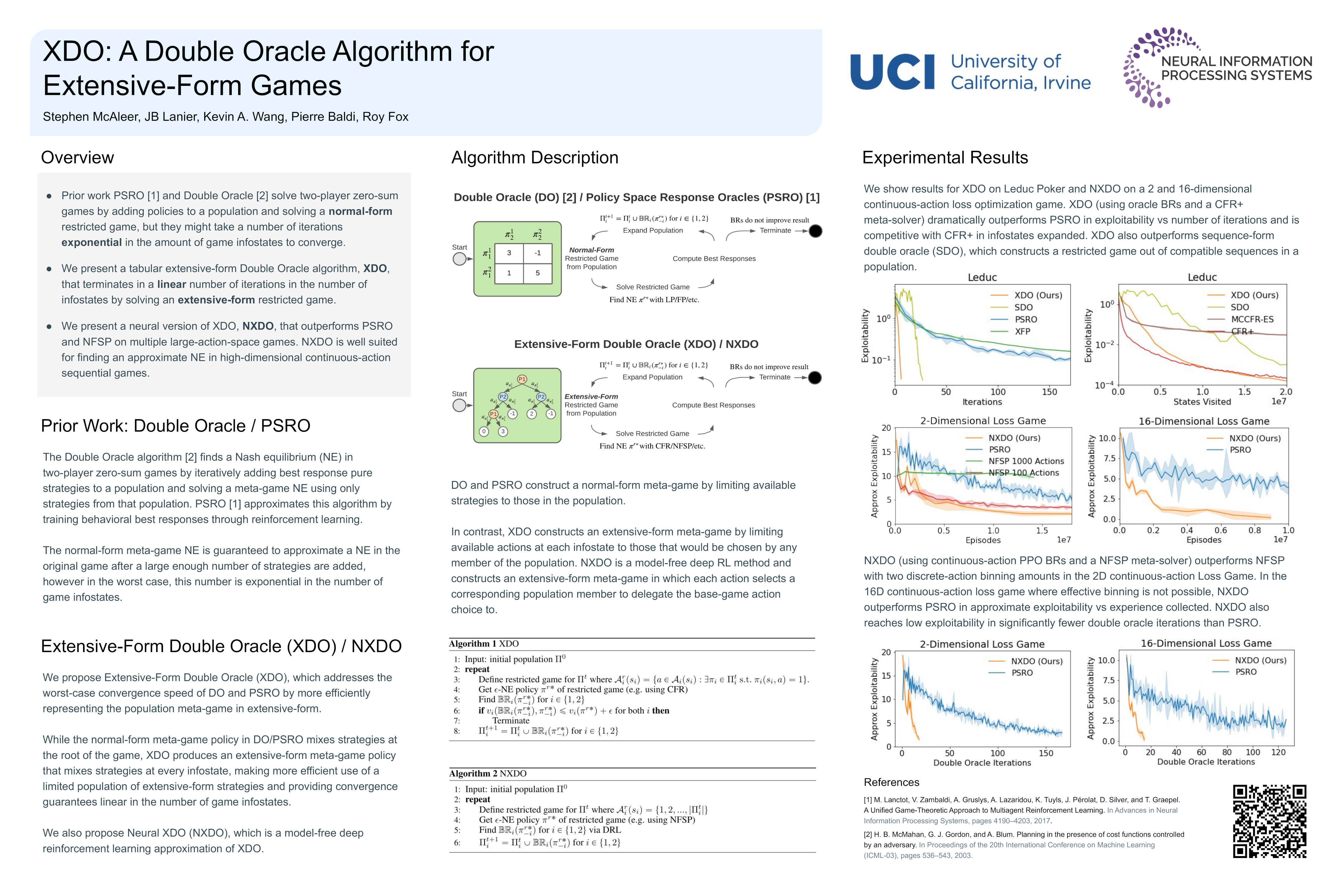
XDO: A Double Oracle Algorithm for Extensive-Form Games
Stephen McAleer, JB Lanier, Kevin Wang, Pierre Baldi, and Roy Fox
35th Conference on Neural Information Processing Systems (NeurIPS), 2021
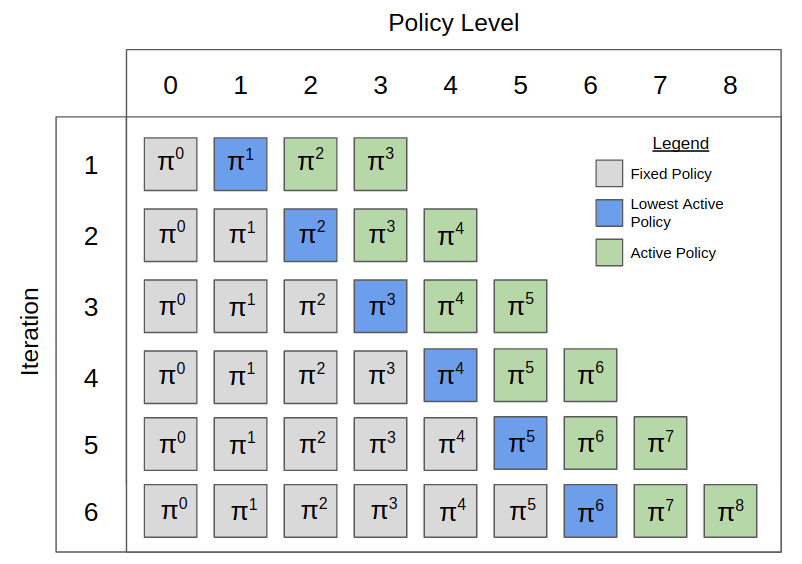
Pipeline PSRO: A Scalable Approach for Finding Approximate Nash Equilibria in Large Games
Stephen McAleer*, JB Lanier*, Roy Fox, and Pierre Baldi
34th Conference on Neural Information Processing Systems (NeurIPS), 2020
An Algorithm and User Study for Teaching Bilateral Manipulation via Iterated Best Response Demonstrations
Carolyn Chen, Sanjay Krishnan, Michael Laskey, Roy Fox, and Ken Goldberg
13th IEEE International Conference on Automation Science and Engineering (CASE), 2017
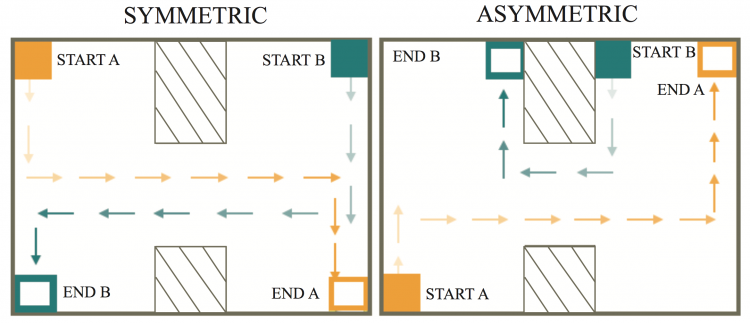
A Multi-Agent Control Framework for Co-Adaptation in Brain-Computer Interfaces
Josh Merel*, Roy Fox*, Tony Jebara, and Liam Paninski
27th Conference on Neural Information Processing Systems (NeurIPS), 2013
Workshops
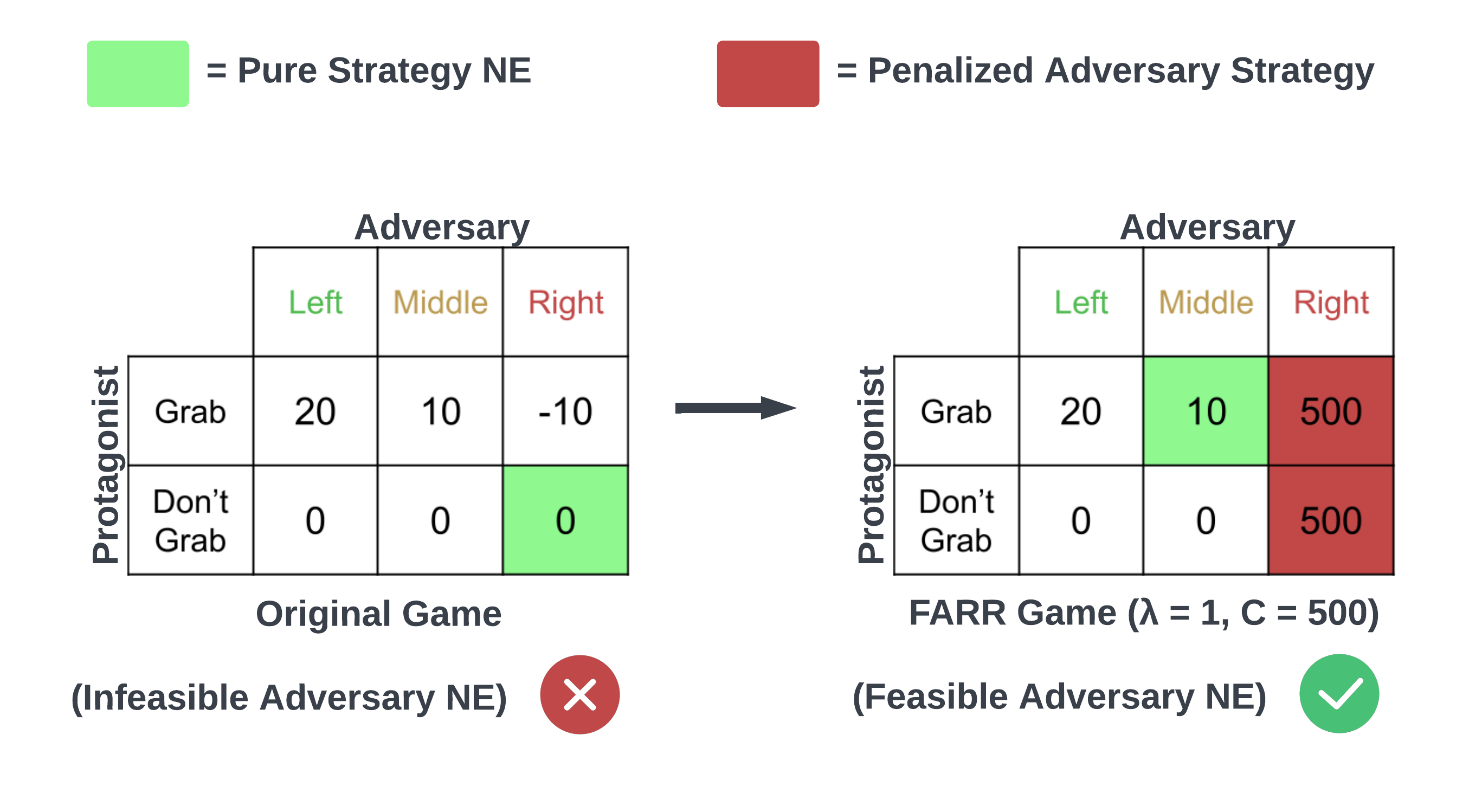
Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments
JB Lanier, Stephen McAleer, Pierre Baldi, and Roy Fox
Deep Reinforcement Learning workshop (DRL @ NeurIPS), 2022
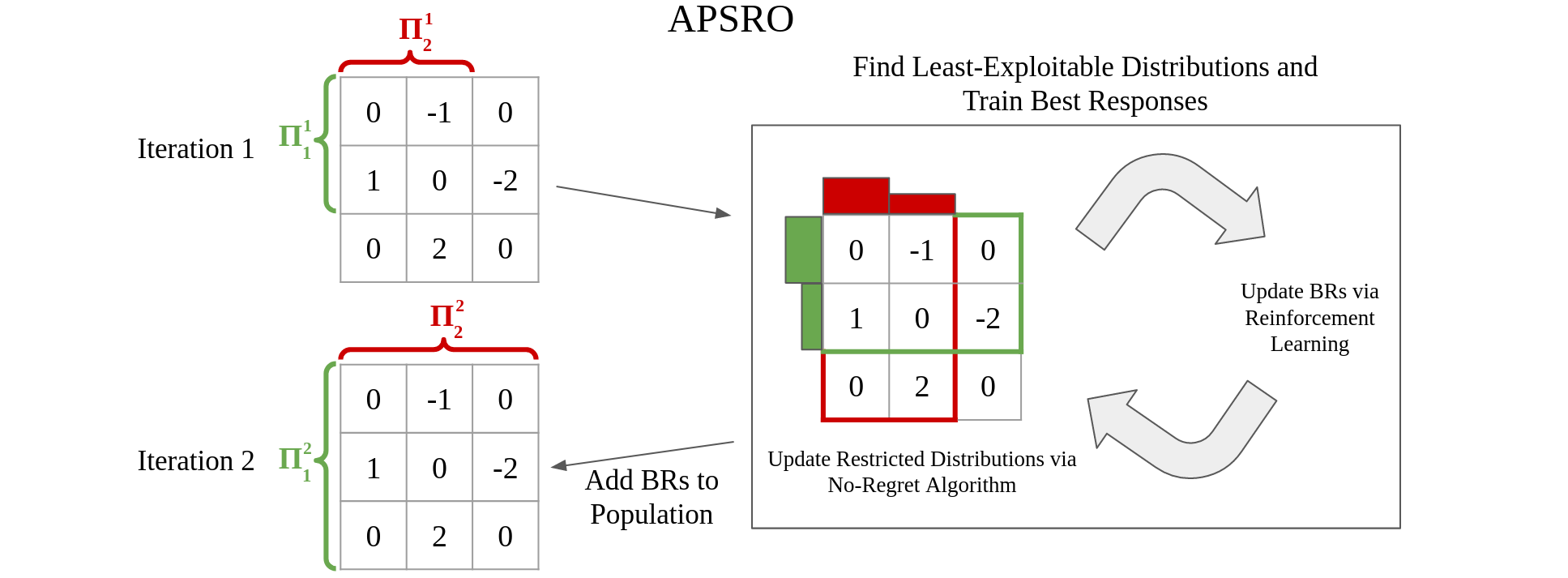
Anytime PSRO for Two-Player Zero-Sum Games
Stephen McAleer, Kevin Wang, JB Lanier, Marc Lanctot, Pierre Baldi, Tuomas Sandholm, and Roy Fox
Reinforcement Learning in Games workshop (RLG @ AAAI), 2022
CFR-DO: A Double Oracle Algorithm for Extensive-Form Games
Stephen McAleer, JB Lanier, Pierre Baldi, and Roy Fox
Reinforcement Learning in Games workshop (RLG @ AAAI), 2021
{kind=link}
{kind=link}