Modular Framework for Visuomotor Language Grounding
Kolby Nottingham, Litian Liang, Daeyun Shin, Charless Fowlkes, Roy Fox, and Sameer Singh
Embodied AI workshop (EmbodiedAI @ CVPR), 2021
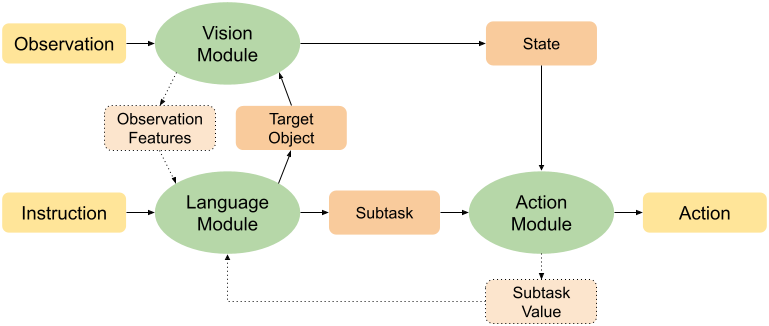
Natural language instruction following tasks serve as a valuable test-bed for grounded language and robotics research. However, data collection for these tasks is expensive and end-to-end approaches suffer from data inefficiency. We propose the structuring of language, acting, and visual tasks into separate modules that can be trained independently. Using a Language, Action, and Vision (LAV) framework removes the dependence of action and vision modules on instruction following datasets, making them more efficient to train. We also present a preliminary evaluation of LAV on the ALFRED task for visual and interactive instruction following.